EXPLICIT MEMORY MANAGEMENT
#Dynamic Memory Allocation

- Explicit vs. Implicit Memory Allocator
- Explicit: 응용프로그램이 공간을 할당하고 free한다
- 예: malloc and free in C
- Implicit: 응용 프로그램에서 공간을 할당하지만 free하지 않는다
- 예: Java, ML or Lisp와 같은 언어의 garbage collection
- Explicit: 응용프로그램이 공간을 할당하고 free한다
- Allocation
- 두 경우 모두 메모리 할당자는 블록 집합으로 메모리의 추상화를 제공한다
- 사용 가능한 메모리 블록을 애플리케이션에 배포한다
#Process Memory Image
할당자가 sbrk 함수를 사용하여 운영 체제에서 추가 힙 메모리를 요청한고, 힙의 초기 시작은 랜덤화된다(일반적으로 .bss의 끝보다 약간 높음).
#The Malloc API
#include <stdlib.h>
void *malloc(size_t size)
- 성공하는 경우
- 8바이트 경계에 정렬된 최소 크기 바이트(일반적으로)의 메모리 블록으로 포인터를 반환한다. 다른 정렬 (alignments)에는 memalign()을 사용한다
- size == 0이면 NULL 또는 해제해야 하는 포인터를 반환할 수 있다(플랫폼에 따라 다름).
- 실패 시: NULL(0)을 반환하고 errno를 설정한다
void free(void *p)
- p 단위로 표시된 블록을 사용 가능한 메모리 풀로 반환한다
- p는 malloc 또는 realloc에 대한 이전 호출에서 와야 한다
void *realloc(void *p, size_t size)
- 블록 p의 크기를 변경하고 포인터를 새 블록으로 되돌린다
- 이전 및 새 크기 최소값까지 변경되지 않은 새 블록의 내용
*이 포스트 에서 가정하고 있는 사항: 메모리는 word addressed 됨(각 word는 포인터를 가질 수 있음)
#Allocation 예제
#Constraints / 제약
- Applications: (클라이언트)들은
- 임의의 할당 순서 및 free 요청 가능
- free 요청은 할당된 블록에 해당해야 한다
- Allocators:
- 할당된 블록의 수 또는 크기를 제어할 수 없다
- 모든 할당 요청에 즉시 응답해야 함
- 즉, 요청을 재주문하거나 버퍼링할 수 없다
- 사용 가능한 메모리에서 블록을 할당해야 한다
- 즉, 할당된 블록을 빈 메모리에만 배치할 수 있다
- 또한, 관리하는 메모리에 필요한 모든 데이터 구조를 유지해야 한다
- 모든 정렬 요구 사항을 충족할 수 있도록 블록을 정렬해야 한다
- 예: 리눅스 box의 GNU malloc(libc malloc)에 대한 8바이트 정렬
- 사용 가능한 메모리만 조작 및 수정할 수 있다
- 할당된 메모리를 건들면 안됨
- 할당된 블록이 할당된 후에는 이동할 수 없다
- 즉, compaction이 허용되지 않
#malloc/free 디자인 목표
- 주요 목표
- malloc 및 free에 적합한 성능
- 이상적으로는 constant time / O(1) 이어야 한다(항상 가능한 것은 아님)
- 블록 수에 선형 시간이 걸리지 않아야 한다
- 효율적인 공간 활용도
- 사용자 할당 구조("payload")는 힙의 큰 부분이어야 한다
- "Fragmentation"을 최소화하고자 함
- malloc 및 free에 적합한 성능
- 추가 목표
- 좋은 집약적 특성 (locality properties)
- 시간적으로 가까운 곳에 할당된 구조는 공간적으로 가까워야 한다
- "유사한" 객체는 공간에 가깝게 할당되어야 한다
- Robust
- free(p1)이 유효한 할당된 개체 p1에 있는지 확인할 수 있어야 한다
- 메모리 참조가 할당된 공간에 있는지 확인할 수 있어야 한다
- 좋은 집약적 특성 (locality properties)
#성능 목표: Throughput
- malloc 및 free 요청의 일부 시퀀스가 주어졌을때,
- R0', R1', ..., Rk', ... , Rn-1
- 처리량 및 최대 메모리 활용률을 극대화
- 이러한 목표는 종종 상충된다
- 할당자의 성능은 요청의 특정 특성에 따라 달라진다
- Throughput
- 단위 시간당 완료된 요청 수
- 예시: 10초 동안 5,000건의 malloc call과 5,000건의 free call일때, 처리량(Throughput)은 초당 1,000개의 작업이다
#성능 목표: Peak Memory Utilization
- malloc 및 free 요청의 일부 시퀀스가 주어졌을때,
- R0', R1', ..., Rk', ... , Rn-1
- Def: 총 페이로드 Pk
- malloc(p)는 p바이트의 페이로드를 갖는 블록을 초래한다
- 요청 Rk가 완료된 후 총 페이로드 Pk는 현재 할당된 페이로드의 합계이다
- 현재 힙 크기는 Hk로 표시됨
- Peak memory utilization:
- k개의 요청 후 최대 메모리 사용률은 다음과 같다
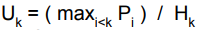
- 할당된 모든 것과 아직 비어 있지 않은 것의 비율 vs 할당자가 사용하고 있는 공간의 양(합계 할당이 최고조에 달했을 때 고려됨)

#Internal Fragmentation
- 단편화(Fragmentation)로 인한 메모리 활용률 저하
- 내부 및 외부 단편화의 두 가지 형태
- Internal fragmentation (내부 단편화)
- 모든 블록에서 내부 fragmentation은 블록 크기와 페이로드 크기 간의 차이이다
- 힙 데이터 구조 유지 관리, 정렬을 위한 패딩 또는 명시적 정책 결정(예: 블록을 분할하지 않음)으로 인해 발생한다
- 이전 요청 패턴에만 의존하므로 쉽게 측정할 수 있다

#External Fragmentation
Aggregate 힙 메모리가 충분하지만 단일 사용 가능한 블록이 충분히 크지 않을 때 발생한다. 할당자가 sbrk()를 통해 더 많은 메모리를 확보해야 하며 (결국) 메모리가 부족해질 수 있다. 또한 외부 단편화는 향후 요청 패턴에 따라 달라지므로 측정하기가 어렵다.

#구현 문제 (Implementation Issues)
- 포인터가 주어졌을 때 얼마나 많은 메모리를 확보할 수 있는지 어떻게 알 수 있을까?
- free()는 길이를 인자로 받지 않는다
- free 블록을 어떻게 추적할까?
- 빈 블록보다 작은 구조를 할당할 때 여유 공간을 어떻게 해야하나?
- 요청에 맞는 할당에 사용할 블록을 어떻게 선택해야 할까?
- 자유 블록을 힙에 어떻게 다시 삽입할까?
#Knowing How Much to Free
- 표준방법
- 블록 앞에 있는 단어의 블록 길이를 유지
- 이 단어는 종종 헤더 필드 또는 헤더라고 불린다
- 할당된 모든 블록에 대해 추가 word 필요
- 블록 앞에 있는 단어의 블록 길이를 유지

#Keeping Track of Free Blocks
- 방법 1: 길이를 사용한 Implicit list - 모든 블록을 링크

- 방법 2: 프리 블록 내의 포인터를 이용한 프리 블록 간의 Explicit list

- 방법 3: Segregated free list:
- 크기별 클래스에 대한 다른 free list
- 방법 4: 크기별로 정렬된 블록
- 각 free 블록 내에 포인터가 있는 균형 트리(예: Red-Black tree)와 key로 사용되는 길이를 사용할 수 있다
#방법1: Implicit (Free) List
- 각 블록이 비어 있는지 또는 할당되었는지 식별해야 함
- 추가 word를 사용하면 안됨 – 마지막 비트 도용(크기가 2의 배수이므로 가능)
- 크기를 읽을 때 낮은 차수의 비트를 마스킹

#Implicit List: Finding a Free Block
- First fit
- 처음부터 검색 list, 적합한 첫 번째 자유 블록을 선택
- 총 블록 수(할당 및 사용 가능)에서 선형 시간이 걸릴 수 있음
- List 시작 부분에 "splinters"가 발생할 수 있다
- Next fit
- First-fit과 유사하지만 이전 검색 종료 위치의 검색 list
- 많은 연구나 논문에서는 단편화 (Fragmentation)가 더 나쁘다는 것을 시사
- Best fit
- list을 검색하고 가장 가까운 크기의 빈 블록을 선택
- fragment를 작게 유지한다. 일반적으로 단편화를 완화시킴
- 일반적으로 first-fit보다 느리게 실행됨
p = start;
while ((p < end) || // not passed end
(*p & 1) || // already allocated
(*p <= len)) // too small
p = p + (*p & ~1);#Implicit List: Allocating in Free Block
- free 블록에 할당 - 분할
- 할당된 공간이 사용 가능한 공간보다 작을 수 있으므로 블록을 분할할 수 있다

void split(ptr p, int len) {
int newsize = ((len + 1) >> 1) << 1; // add 1 and round up
int oldsize = *p & ~1; // mask out low bit
*p = newsize | 1; // set new length
if (newsize < oldsize)
*(p+newsize) = oldsize - newsize; // set length in remaining
} // part of block#Implicit List: Freeing a Block
- 가장 간단한 구현
- 할당된 플래그만 지우면 된다
- void free_block(ptr p) { *p = *p & -2}
- 하지만 "false fragmentation"으로 이어질 수 있다
- 할당된 플래그만 지우면 된다

사용 가능한 공간이 충분하지만 할당자가 찾을 수 없게 된다
#Implicit List: Coalescing
- 다음 및/또는 이전 블록이 비어 있는 경우 join(coalesce)
- 다음 블록과 병합

void free_block(ptr p) {
*p = *p & -2; // clear allocated flag
next = p + *p; // find next block
if ((*next & 1) == 0)
*p = *p + *next; // add to this block if
} // not allocated#Implicit List: Bidirectional Coalescing
- Boundary tags
- 사용 가능한 블록의 맨 아래에 크기/할당된 word 복제
- "list"을 뒤로 넘나들 수 있지만 추가 공간이 필요

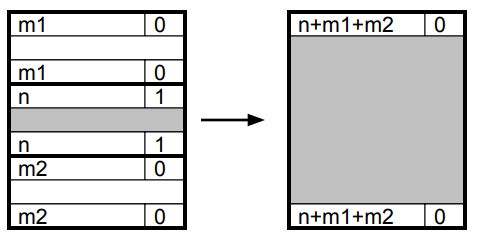
#Constant Time / O(1) Coalescing
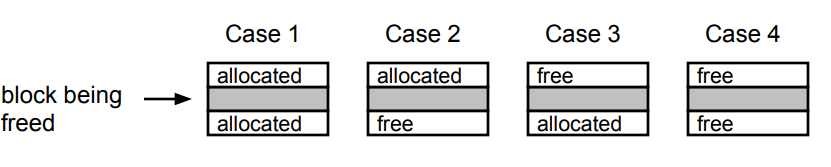
#Case1

#Case2

#Case3

#Case4
#Summary of Key Allocator Policies
- Placement policy
- First fit, next fit, best fit, etc
- 더 낮은 처리량과 더 적은 fragmentation를 비교
- Interesting observation: 분리된 free list(나중에 공개됨)은 전체 free list을 검색하지 않고 최적의 배치 정책을 근사화한다
- Splitting policy
- 언제 free 블록을 분할할까?
- 우리는 얼마나 많은 내부 fragmentation을 용인할 의향이 있는가
- Coalescing policy
- 즉시 병합 (Immediate coalescing): 빈 블록이 호출될 때마다 인접 블록을 병합한다
- 지연 병합 (Deferred coalescing): 필요 시까지 병합을 연기하여 free의 성능을 개선한다. 예를 들어:
- malloc에 대한 free list을 스캔할 때 병합
- external fragmentation의 양이 일부 임계값에 도달하면 병합
#Implicit Lists: Summary
- 구현은 간단하다
- 할당: 최악의 경우 선형 시간(linear time / O(n))
- free: O(1) worst case time complextiy - 병합을 고려하더라도
- 메모리 사용량: 배치 policy에 따라 달라진다
- First fit, next fit or best fit
- 선형 시간 할당으로 인해 malloc/free에 대해 실제로 사용되지 않음
- 많은 특수 용도 응용 프로그램에 사용
- 그러나 분할 및 경계 태그 병합의 개념은 모든 할당자에게 일반적이다
#방법2: Explicit (Free) Lists
- 링크 포인터에 데이터 공간 사용
- 일반적으로 doubly-linked list사용
- 병합(coalescing)을 위해 경계 태그(boundary tag)가 여전히 필요
- 링크는 반드시 블록과 같은 순서일 필요는 없다


#Allocated vs. Free Blocks
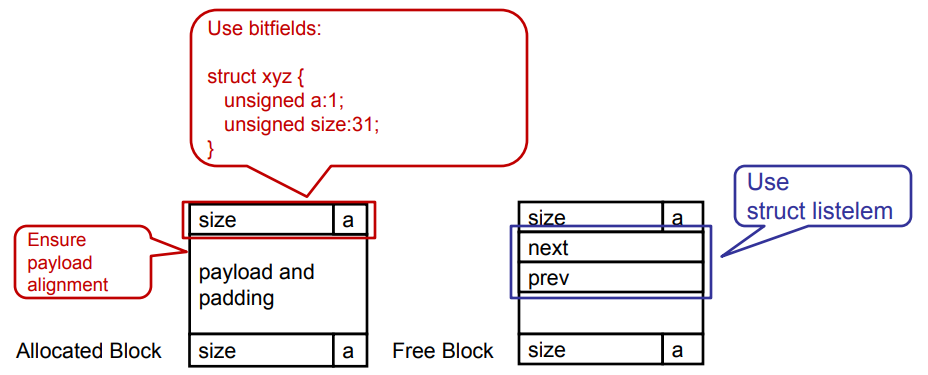
#Splitting & Explicit Free Lists

참고: 프리 블록이 프리 리스트의 동일한 위치에 있는 경우, 블록의 하단에서 분리될 수도 있다. 포인터 조작이 필요하지 않다
#Freeing With Explicit Free Lists
- insertion policy: 새로 해방된 블록을 프리 리스트의 어디에 둘까?
- LIFO (last-in-first-out) policy
- 사용 가능한 목록의 시작 부분에 사용 가능한 블록 삽입
- 장점: 단순하고 constant time / O(1)
- 단점: 연구나 논문들은 단편화가 Address-ordered보다 더 나쁘다는 것을 시사함
- Address-ordered policy
- 사용 가능한 목록 블록이 항상 주소 순서대로 정렬되도록 사용 가능한 블록 삽입
- 예시: addr(pred) < addr(curr) < addr(succ)
- 장점: 연구에 따르면 단편화가 LIFO보다 낫다고 시사함
- 단점: 검색 필요
- 사용 가능한 목록 블록이 항상 주소 순서대로 정렬되도록 사용 가능한 블록 삽입
- LIFO (last-in-first-out) policy
#Freeing With a LIFO Policy
- Case 1: a-a-a
- free list의 시작 부분에 self 삽입

- Case 2: a-a-f
- next를 분할하고, self와 다음을 병합하고, free list의 시작 부분에 추가

- Case 3: f-a-a
- Prev를 분리하여 self와 병합하고 free list의 시작 부분에 추가

- Case 4: f-a-f
- prev와 next을 분리하고, self와 병합하며, list의 시작에 추가

#Explicit List Summary
- Implicit list와 비교
- 할당은 전체 블록이 아닌 사용 가능한 블록 수의 선형 시간이다. 대부분의 메모리가 꽉 찼을 때 할당 속도가 훨씬 빠르다
- 블록을 목록 안팎으로 분할해야 하므로 할당이 조금 더 복잡하고 여유 있음
- 링크를 위한 추가 공간(각 블록에 대해 2개의 추가 word 필요)
- linked list의 주요 용도는 분리된 free list와 함께 사용된다
- 크기가 서로 다른 클래스 또는 서로 다른 유형의 개체에 대해 연결된 여러 목록 유지
#방법3: Segregated free list
- Segregated Storage
- 각 크기 클래스에는 자체 블록 모음이 있다
- 작은 크기마다 별도의 크기 클래스가 있는 경우가 많다(2,3,4,…)
- 더 큰 크기의 경우 각 ^2 (2 제곱승)에 대해 크기 클래스를 가질 수 있다

#Simple Segregated Storage
- 각 크기 클래스에 대해 별도의 힙 및 사용 가능한 list
- 분할 없음
- 크기 n의 블럭을 할당하려면
- 크기 n에 대한 free list가 비어 있지 않으면
- list에 첫 번째 블록 할당(참고, list는 implicit이거나 explicit일 수 있음)
- free list가 비어 있으면
- 새로운 page가져오기
- 페이지의 모든 블록에서 새로운 무료 목록 만들기
- 첫 번째 블록을 목록에 할당
- Constant time / O(1)
- 크기 n에 대한 free list가 비어 있지 않으면
- 블록을 free하려면
- free list에 추가
- 페이지가 비어 있으면 다른 크기로 사용할 수 있도록 페이지를 반환(선택 사항)
- Tradeoffs
- 빠르지만 심하게 fragmentation 발생가능

#Segregated Fits
- 일부 크기 클래스에 대해 각각 하나씩 사용 가능한 list array
- 크기 n의 블럭을 할당하려면
- m > n 크기의 블록에 대한 적절한 free list 검색
- 적절한 블록이 발견되면
- 블록을 분할하여 적절한 list에 fragment 배치(선택 사항)
- 적절한 블록이 없으면 다음번으로 큰 클래스를 시도
- 블록이 발견될 때까지 반복
- 블록을 free하려면
- 병합(Coalesce)하여 적절한 list에 배치(선택 사항)
- Tradeoffs
- 순차적 적합치 / sequential fits(즉, 두 가지 크기 클래스의 power에 대한 로그 시간)보다 빠른 검색
- 단순 분리 스토리지의 단편화 (fragmentation) 제어
- 병합(Coalesce)을 통해 검색 시간 증가될 수 있음
- 이 경우 지연 병합(Deferred coalescing)이 도움이 될 수 있음

'Computer Science > Computer Systems' 카테고리의 다른 글
| [Lecture 19] Networking / 네트워킹 (1) | 2022.11.19 |
|---|---|
| [Lecture 18] Virtual Memory / 가상 메모리: Principles and Mechanisms (0) | 2022.11.19 |
| [Lecture 14] 멀티쓰레딩 VIII - Atomic Variables and Operations (0) | 2022.10.19 |
| [Lecture 13] 멀티쓰레딩 VII - Performance (0) | 2022.10.19 |
| [Lecture 12] 멀티쓰레딩 VI - Atomicity Violations (0) | 2022.10.19 |



