
[Lecture 7] 멀티쓰레딩 - Introduction to Multithreading
#멀티태스킹
우리가 새로운 게임이 출시되었을때, 게임웹사이트에 들어가 다운로드를 하는데 다운로드를 하는 동안 컴퓨터 전체가 멈춰있으면 어떨까? 오래전 컴퓨터들은 이러한 작업을 한번에 하나밖이 실행 하지 못했기 때문에, 여러작업을 동시에하는 현대 컴퓨터와는 달리 굉장히 불편했다. 하지만 현재 컴퓨터들은 프로세스 여러개를 한번에 돌릴수 있기 때문에 이러한 불편함을 없앨 수 있었다.
바로 이렇게 컴퓨터가 여러개의 프로세스, 작업을 동시에 여러 개 실행하는 것이 멀티 태스킹이다. CTRL - Shift - ESC를 눌러보면 얼마나 많은 프로세스들이 백그라운드에서 돌아가고 있는지 볼 수 있다. 여러 프로세스를 함께 실행시키는 작업은 동시적 (concurrency), 병렬적 (parallel), 또는 둘의 혼합으로 이루어 질 수 있다.
동시성(concurrency)은 프로세스 하나가 여러 프로세스/작업를 옯겨다니면서 일부분씩 진행한다. 이렇게 여러 프로세스/작업을 바꾸는 행위를 context-switching이라고 한다 (Lecture 1-1 참조).
병렬성(parallel)은 프로세서 하나에 코어 여러개가 달려서, 동시에 작업을 수행하는 것을 말한다, 우리가 요즘 컴퓨터에서 흔히 들어본 멀티 코어 프로세서가 달린 컴퓨터에서 실행가능하다.

#쓰레드
우리가 위에서 여러개의 프로세스들이 동시에 실행될 수 있다는 것을 알아봤다. 하지만 여러 프로세스만 동시에 실행시킬 수 있다면 모든 문제가 해결될까? 아니다, 우리가 프로세스가 여러개가 실행돼야하는것처럼, 프로세스 안에서도 여러개 갈래의 작업들이 동시에 진행되어야 한다. 이 갈래들을 우리는 "쓰레드 (Thread)" 라고 부른다
#Threads vs Processes
쓰레드란 프로세스보다도 작은 프로세스 안에서 실행되는 흐름의 최소 단위이다
프로세스란 프로그램이 CPU한테 메모리를 할당받아서 실행되고 있는 프로그램이다
- 프로세스는 시스템/머신 내에서 제어의 동시적이고 개별적인 논리적 흐름을 제공한다
- 스레드는 프로세스 내에서 별도의 논리적 제어 흐름을 제공한다.
스레드는 프로세스와는 다르게 모든 데이터와 리소스를 공유하지만 각각 별도의 스택과 실행 상태를 유지한다.
#멀티쓰레딩
멀티쓰레딩은 CPU가 한번에 처리할 수 있는 작업 실행 단위가 1개가 아닌 여러개가 될 수 있는 기능을 말한다. 멀티쓰레딩은 멀티태스킹보다 한 단계 더 진보된 개념으로서 멀티태스킹이 프로그램간의 멀티태스킹을 의미한다면, 멀티쓰레딩은 프로그램 내에서 멀티태스킹을 구현한 것이라고 볼 수 있다.
멀티쓰레딩 컴퓨터는 여러 개의 쓰레드를 효과적으로 실행할 수 있는 하드웨어 지원을 갖추고 있다. 이는 쓰레드가 모두 같은 주소 공간에서 동작하여 하나의 CPU 캐시 공유 집합과 하나의 변환 색인 버퍼 (TLB)만 있는 멀티프로세서 시스템 (멀티 코어 시스템)과는 구별한다. 그러므로 멀티쓰레딩은 프로그램 안에서 병렬 처리의 이점을 맛볼 수 있지만 멀티프로세싱 시스템은 여러 개의 프로그램들을 병렬로 처리할 수 있다. 멀티프로세싱 시스템이 여러 개의 완전한 처리 장치들을 포함하는 반면 멀티쓰레딩은 쓰레드 수준뿐 아니라 명령어 수준의 병렬 처리에까지 신경을 쓰면서 하나의 코어에 대한 이용성을 증가하는 것에 초점을 두고 있다.
#Application Level에서의 동시성(Concurrency)
- 대부분의 범용 OS는 이미 프로세스를 동시에 실행할 수 있는 기능을 제공한다. 많은 응용 프로그램에서 우리는 프로세스 내에서 여러 개의 동시 연산을 요구한다. 아래 예시를 한번 보자:
- 병렬 컴퓨팅 (Parallel Computing): 여러 작업을 수행하거나 동시에 데이터 공유 작업이다. 쉽게 말해, 많은 계산 또는 프로세스가 동시에 수행되는 계산의 한 유형이다
- 오버랩 I/O & Computation: 파일 공유 프로그램에서 다운로드하는 동안 체크섬 (검사합) 및 복구
- 백그라운드 작업을 수행하는 동안 UI 제공(맞춤법 검사, auto suggestion 의 경우 서버 또는 백엔드에 요청)
- 네트워크 서버에서 여러 클라이언트를 동시에 처리
이러한 애플리케이션 레벨 동시성은 여러개의 실행 스레드를 갖는 것에 의해 지원된다.
#Implementing Threads
#Thread Java 구현
class ThreadDemo implements Runnable {
Thread t;
ThreadDemo() {
t = new Thread(this, "Thread");
System.out.println("Child thread: " + t);
t.start();
}
public void run() {
try {
System.out.println("Child Thread");
Thread.sleep(50);
} catch (InterruptedException e) {
System.out.println("The child thread is interrupted.");
}
System.out.println("Exiting the child thread");
}
}
public class Demo {
public static void main(String args[]) {
new ThreadDemo();
try {
System.out.println("Main Thread");
Thread.sleep(100);
} catch (InterruptedException e) {
System.out.println("The Main thread is interrupted");
}
System.out.println("Exiting the Main thread");
}
}#Thread c 구현
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void* func(void* arg)
{
// detach the current thread
// from the calling thread
pthread_detach(pthread_self());
printf("Inside the thread\n");
// exit the current thread
pthread_exit(NULL);
}
void fun()
{
pthread_t ptid;
// Creating a new thread
pthread_create(&ptid, NULL, &func, NULL);
printf("This line may be printed"
" before thread terminates\n");
// The following line terminates
// the thread manually
// pthread_cancel(ptid);
// Compare the two threads created
if(pthread_equal(ptid, pthread_self())
printf("Threads are equal\n");
else
printf("Threads are not equal\n");
// Waiting for the created thread to terminate
pthread_join(ptid, NULL);
printf("This line will be printed"
" after thread ends\n");
pthread_exit(NULL);
}
// Driver code
int main()
{
fun();
return 0;
}동시성과 병렬성 같은 여러 제어 흐름을 유지하기 위해서는 기본적으로 OS 커널의 지원이 필요한 것일까, 아니면 사용자 수준에서 non-privileged instructions와 같은 기능을 활용하여 라이브러리 등을 통해 구현할 수 있는 것일까?
#협력적 멀티 쓰레딩 / Cooperative Multi-Threading
협력적이라 함은 각 스레드가 자체적으로 CPU 사용 시간을 결정하고, 다른 스레드가 사용할 수 있도록 어느 시점에 CPU를 양보할지를 스스로 결정한다는 의미다.
실제로는 커널 수준의 지원 없이도 여러 제어 흐름을 완전히 관리할 수 있다. 이는 코루틴이나 사용자 레벨 스레드로 알려진 다양한 언어의 변형에 따라 존재한다. 실행 상태를 저장하고 복원할 수 있는 기본 연산이 필요하다.
비선점 모델에서는 스레드가 자발적으로 CPU 접근을 하지 않는 한, 다른 스레드에 의해 CPU 접근이 선점되지 않는다. 산출량(yield)은 지시되거나 지시되지 않은 다음 실행 대상을 가리킬 수 있으며, 이는 예를 들어 uthreads에서 볼 수 있다.
일부 고급 언어에서는 함수가 실행 상태가 저장되고 복원될 때 임시 결과를 'yield'할 수 있다. 이는 파이썬 또는 ES6의 'yield'와 같은 개념이다. 이러한 방식은 비동기 I/O와도 결합될 수 있으며, 진행 중인 작업을 나타내는 promise 객체와 async/await를 사용하여 구현할 수 있다.
| 장점 | 단점 |
| OS 지원 필요 없음 매우 빠른 context-switching 예를 들어 x++와 같은 특정 데이터 레이스가 없음 비동기 I/O와 결합하면 확장 가능한 설계 가능 |
여러 CPU를 사용할 수 없음 오래 실행되거나 uncooperative 스레드를 쉽게 선점할 수 없음 I/O 시스템 호출을 차단하면 모든 스레드/전체 프로세스가 차단됨 |
#Kernel-supported Threads
OS 커널이 스레드 관리를 직접 담당하게 되면, 앞서 언급된 여러 제약 사항들을 해결할 수 있다. 이는 OS가 스레드를 서로 다른 CPU에 할당할 수 있게 해주어, 병렬 처리를 통한 성능 향상이 가능하게 만든다. I/O 작업을 수행할 때, OS는 해당 작업을 요청한 스레드만을 BLOCKED 상태로 전환시키는 방식을 채택한다. 또한, OS의 사전 스케줄링 모델은 스레드 간의 강제적인 중단과 준비 상태로의 전환 없이도 CPU 접근을 공유할 수 있게 한다. 현재 대부분의 주요 운영 체제에서 지원되는 이 모델은 커널 레벨 스레딩이라고 불리며, 사용자 레벨 스레딩과는 대조되는 개념이다. 이는 순수 커널 스레드와는 별개로, 종종 경량 프로세스(Lightweight Process)로도 언급된다.
#Hybrid Models
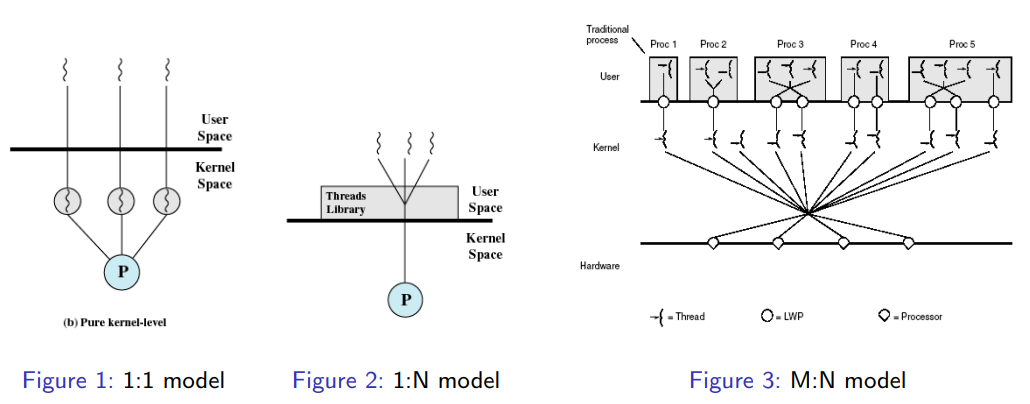
- Pure user-level threading은 1:N 모델을 사용한다(N개의 user-level 스레드는 1개의 OS-level 스레드를 공유함).
- Pure kernel-level threading은 1:1 모델(각 사용자 스레드에 대해 1개의 OS 스레드)을 사용한다
- 하이브리드(M:N) 모델은 사용자 레벨 및 커널 지원 스레드의 최고 수준을 얻으려고 한다 (예: Windows 파이버, Solaris M:N 모델)
하이브리드 모델은 순수 사용자 레벨 스레딩의 1:N 모델(N개의 사용자 레벨 스레드가 1개의 OS 레벨 스레드를 공유)과 순수 커널 레벨 스레딩의 1:1 모델(각 사용자 스레드에 대해 하나의 OS 스레드) 사이의 균형을 찾고자 한다. 예를 들어, Windows의 파이버나 Solaris의 M:N 모델과 같은 경우가 이에 해당한다. 그러나 이러한 모델의 복잡성은 대부분의 경우 M:N 모델의 사용을 저해하고, 1:1 모델의 비용 절감 및 최적화를 위한 노력으로 방향을 전환시켰다.
#POSIX Threads “Pthreads”
POSIX 스레드, 즉 Pthreads는 병렬적으로 동작하는 소프트웨어 개발을 위해 제공되는 실행 모델과 표준 API이다. Pthread는 일반적으로 모든 UNIX 계열 POSIX 시스템에서 사용되며, UNIX와는 다른 길을 걷고 있는 Windows에서도 여러 이유로 지원된다. 예를 들어, pthread-w32를 사용하면 Windows 환경에서도 Pthread API의 부분 집합을 사용할 수 있다. 또한, Pthread는 전체적인 POSIX 표준의 확장으로서, 전통적인 프로세스 기반 시설과 스레드 간의 상호 작용을 정의한다. 자바 스레드, C++ async와 같이 많은 고급 언어들이 Pthread에 대한 직접적인 바인딩을 제공하며, Pthread 라이브러리에서 제공하는 함수들은 pthread.h를 포함하여 사용할 수 있다.
- pthread_ t : 스레드 핸들러
- pthread_attr_t : 스레드 성질
#C언어 예제 (Create와 Join)
//struct
struct thread_info {
const char * msg;
};
static void *
thread_function(void *_arg)
{
struct thread_info *info = _arg;
printf("Thread 1 runs, "
"msg was `%s'\n",info->msg);
return (void *) 42;
}//main fuction
int
main()
{
struct thread_info info = {
.msg = "Hello, Thread" };
pthread_t t;
pthread_create(&t, NULL,
thread_function, &info);
uintptr_t status;
pthread_join(t, (void **) &status);
printf("Status %lu\n", status);
return 0;
}#Java 예제 (Create와 Join)
public class JavaThread
{
static class Example implements Runnable{
String msg;
int result;
Example(String msg) {
this.msg = msg;
}
@Override
public void run() {
System.out.println(msg);
result = 42;
}
}public static
void main(String []av) throws Exception{
var ex = new Example("Hello Thread");
Thread t = new Thread(ex);
t.start();
t.join();
System.out.println(ex.result);
}
}#Concurrency Management
동시성 관리에서, 특히 소규모의 응용 프로그램에서는 개별 작업마다 새로운 스레드를 생성하는 것이 아니라 필요한 스레드 수를 관리하고 작업을 스레드에 분배하는 방식을 채택한다. 스레드의 과다 생성은 리소스 경합과 관리 오버헤드를 증가시키는 반면, 너무 적은 스레드 수는 CPU/코어의 활용도를 저하시킨다. 따라서, 준비 상태 및 실행 중인 스레드의 수가 코어 수와 거의 동일하게 유지되는 것이 목표다.
- Trade-off:
- 스레드가 너무 많으면 리소스에 대한 경합이 증가하고 이를 관리하는 데 따른 오버헤드가 발생한다.
- 스레드 수가 너무 적으면 CPU/코어의 활용도가 낮아 위험하다
- target: READY + RUNNING 스레드 수가 코어 수와 거의 같음
#Java ExecutorService 예제
import java.util.concurrent.*;
public class FixedThreadPool {
static final int N = 8;
public static void main(String []av) throws Exception {
ExecutorService ex = Executors.newFixedThreadPool(3);
Future<?> f[] = new Future<?>[N];
for (int i = 0; i < N; i++) {
final int j = i;
f[i] = ex.submit(new Callable<String>() {
public String call() {
return "Future #" + j + " brought to you by " + Thread.currentThread();
}
});
}
for (int i = 0; i < N; i++)
System.out.println(f[i].get());
ex.shutdown();
}
}#Parallel Divide-and-Conquer 예제
Result solve(Param problem) {
if (problem.size <= GRANULARITY_THRESHOLD) {
return directlySolve(problem);
}
else {
in-parallel {
Result l = solve(lefthalf(problem));
Result r = solve(rightHalf(problem);
}
return combine(l, r);
}
}실행 프레임워크는 스레드에 병렬로 생성된 작업을 매핑해야 한다.