#Hash Function
하나의 문자열을 보다 빨리 찾을 수 있도록 주소에 직접 접근할 수 있는 짧은 길이의 값이나 키로 변환하는 알고리즘을 수식으로 표현한 것. 즉, 해싱 함수(hashing function) h(k)는 어떤 키 k에 대한 테이블 주소(table address)를 계산하기 위한 방법으로 주어진 키 값으로부터 레코드가 저장되어 있는 주소를 산출해 낼 수 있는 수식을 말한다. 문자열을 찾을 때 문자를 하나하나 비교하며 찾는 것보다는 문자열에서 해시 키를 계산하고 그 키에 해당하는 장소에 문자열을 저장해 둔다면, 찾을 때는 한 번의 해시 키 계산만으로도 쉽게 찾을 수 있게 된다.
또한 해쉬 함수는 임의의 길이의 입력 메시지를 고정된 길이의 출력 값으로 압축시킨다. 이 때문에 데이터의 무결성 검증, 메시지 인증에 사용한다. 해시 함수는 일방향성과 충돌 회피성이라는 두 가지 성질을 만족해야 한다. 먼저, 일방향성은 주어진 해시 값 h에 대해서 H(x)=h를 만족하는 값을 찾는 것이 계산적으로 불가능한 것을 말한다. 충돌 회피성이란 주어진 x에 대해 H(x)=H(y)를 만족하는 임의의 입력 메시지 y(x)x)를 찾는 것이 계산적으로 불가능함을 뜻한다
컴퓨터 암호화 기술에도 사용되어 요약함수·메시지다이제스트함수(message digest function)라고도 한다. 주어진 원문에서 고정된 길이의 의사난수를 생성하는 연산기법이다. 생성된 값은 '해시값'이라고 한다.통신회선을 통해서 데이터를 주고받을 때, 경로의 양쪽 끝에서 데이터의 해시값을 구해서, 보낸 쪽과 받은 쪽의 값을 비교하면 데이터를 주고받는 도중에 여기에 변경이 가해졌는지 어떤지를 확인할 수 있다. 불가역적인 일방향함수를 포함하고 있기 때문에 해시값에서 원문을 재현할 수는 없다. 또한, 같은 해시값을 가진 다른 데이터를 작성하는 것도 극히 어렵다. 이런 특성을 이용해서 통신의 암호화 보조수단이나 사용자 인증, 디지털 서명 등에 응용되고 있다.
[네이버 지식백과]
#Hash Function Details
위에도 언급했듯 해시 함수는 키 값을 가져와서 그것으로부터 정수 값(또는 테이블의 인덱스)을 계산할 수 있는 함수이다
예를 들어, 학생의 ID 번호를 마지막 네 자리로 잘라 10000 차원의 배열 C에 학생 기록을 저장할 수 있다고 가정하면
H(IDNum) = IDNum % 10000ID 번호 X가 주어지면 해당 레코드는 C[H(X))]에 삽입된다. 이 방법은 구현하기 쉽고 실행시간도 저렴할 것이다. 하지만 이 해시 함수가 실제로 좋은 해시 함수인지는 또 다른 문제이다.
N ≤ M인 N개의 레코드와 M 슬롯의 테이블이 있다고 가정하자.
두 레코드를 동일한 슬롯에 매핑하는 것이 상관이 없다면, 레코드를 테이블에 매핑하는 M^N의 다른 방법이 있다.
테이블의 다른 슬롯에 대한 레코드의 서로 다른 완벽한 매핑의 수는 다음과 같다

예를 들어, N = 50 과 M = 100이면 100^50 = 10^100개의 서로 다른 해시 매핑이 있으며, 그 중 오직 10^93개만 완벽하다(10,000,000개 중 1개)
그러나, 우리는 효과적으로 계산 가능한 해시 함수가 필요하다. 즉, 값을 계산하는 것이 효율적으로 가능해야 한다 (따라서 수학적 공식이 필요하다).
많은 일반적인 접근법이 있지만, 아직도 좋고 실용적인 해시 함수의 설계는 여전히 연구와 실험의 주제로 사용되고 있다
#해시 함수 도메인 문제
논리적으로 가능한 키 값들의 집합은 매우 클 수 있다.
프로그램을 컴파일할 때 실제로 발생하는 일련의 주요 값은 훨씬 작아지지만 실제로 어떤 값이 표시될지는 확인하기 전까지는 알 수 없다
일대일 해시 함수가 이상적이다
- Java 프로그램에서 식별자를 해시하기 위한 적절한 테이블 크기를 갖는다.
- 가능한 Java 식별자의 수를 고려한다.
- 두 집합 모두 유한하고 두 번째 집합은 훨씬 더 크다.
따라서 일대일 해시 함수 다음으로 좋은 것은 "uniform" 해시 함수일 것이다. 즉, 테이블의 각 슬롯에 동일한 수의 도메인 값을 매핑하는 것이다.
#간단한 해시 예제
일반적으로 전체 키 값이 해시 결과에 영향을 미치도록 하는 것이 바람직하다(따라서 정수 키의 마지막 k자리를 단순히 잘라내는 것은 대부분의 경우 좋은 생각이 아니다). 문자열 값을 정수 범위로 해시하는 다음 예시를 한번 보자.
public static int sumOfChars(String toHash) {
int hashValue = 0;
for (int Pos = 0; Pos < toHash.length(); Pos++) {
hashValue = hashValue + toHash.charAt(Pos);
}
return hashValue;
}이 함수는 문자열의 모든 요소를 고려한다. 마지막 세 문자로 잘린 문자열 해시 함수는 "hash", "stash", "mash", "trash“에 대해 동일한 정수를 계산한다
#해쉬 함수 기술
- Division / 나누기
- 해시 함수의 첫 번째 순서는 정수 값을 계산하는 것이다.
- 해시 함수가 선택한 테이블 크기에 대해 유효한 인덱스를 생성할 것으로 예상한다면, 그 정수는 아마도 범위를 벗어날 것이다.
- 테이블 크기를 기준으로 정수를 모델링하여 쉽게 해결할 수 있다.
- 테이블 크기가 소수이거나 적어도 작은 소수 요인이 없는 것이 더 나은 이유가 있다.
- Folding
- 키의 부분들은 종종 재결합되거나 함께 폴딩된다
- shift folding: 123-45-6789 ---> 123 + 456 + 789
- boundary folding: 123-45-6789 ---> 123 + 654 + 789
- 비트 연산을 사용하여 효율적으로 수행할 수 있다.
- 문자열의 문자는 함께 x 또는'd가 될 수 있지만, 작은 숫자가 발생한다.
- 문자의 "청크 (예: interger-sized chunk)"들이 xor될수있다
- Mid-square function
- 키를 "square" 한 다음 중간 부분을 결과로 사용한다.
- 예: 3121 ---> 9740641 ---> 406(테이블 크기가 1000인 경우)
- 문자열은 먼저 예를 들어 folding함으로써 숫자로 변환된다.
- 아이디어는 모든 핵심이 결과에 영향을 미치도록 하는 것이다.
- 테이블 크기가 2의 거듭제곱이면 비트 수준에서 효율적으로 수행할 수 있다. 3121 ---> 100101000010011001 ---> 0101000010 (테이블 크기 1024)
- Extraction
- 키의 일부만 사용하여 결과를 계산한다.
- 실제 키 값의 분포와 관련이 있을 수 있다.
#해시 함수 설계
- 잘 설계된 해시 함수는
- 계산이 쉽고 빠르다
- 테이블에서 지원하는 인덱스 범위에 걸쳐 실제로 발생하는 키 값의 균등한 분포를 가지고 있다.
- 수학적으로 일대일로 관련 키 값 집합을 사용한다.
#Scattering 개선
단순 해시 함수는 적어도 경우에 따라 두 개 이상의 키 값을 동일한 정수 값에 매핑할 가능성이 있다. 하지만 설계에 따라 이 수는 더 적어질 수 있다:
public static int sumOfShiftedChars(String toHash) {
int hashValue = 0;
for (int Pos = 0; Pos < toHash.length(); Pos++) {
hashValue = (hashValue << 4) + toHash.charAt(Pos);
}
return hashValue;
}원래 버전은 이 두 문자열을 모두 동일한 테이블 인덱스로 해시했을 것이다. 결함: 요소 위치를 고려하지 않았다
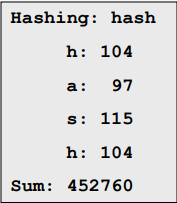
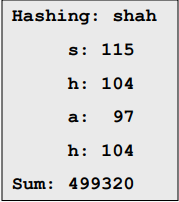
#문자열에 대한 해시함수
문자열 값을 정수로 해시하는 다음 함수를 한번 보자
public static long elfHash(String toHash) {
long hashValue = 0;
for (int Pos = 0; Pos < toHash.length(); Pos++) { // use all elements
hashValue = (hashValue << 4) + toHash.charAt(Pos); // shift/mix
long hiBits = hashValue & 0xF000000000000000; // get high nybble
if (hiBits != 0)
hashValue ^= hiBits >> 56; // xor high nybble with second nybble
hashValue &= ~hiBits; // clear high nybble
}
return hashValue;
}이 해시 함수는 원래 시스템 수준 해시 테이블을 구축하기 위해 유닉스 운영 체제의 설계 중에 개발되었다
이 함수의 trace는 다음과 같다

#Perfect Hash Functions
컴퓨터 과학에서, 집합 S에 대한 완벽한 해시 함수 h는 충돌 없이, S의 고유한 요소들을 m의 정수 집합에 매핑하는 해시 함수이다. 수학적으로 말하면 주입 함수(injective function)에 가깝다.
완벽한 해시 함수는 최악의 경우 접근 시간이 일정한 룩업 테이블을 구현하는 데 사용될 수 있다. 완벽한 해시 함수는 해시 테이블을 구현하기 위해 사용될 수 있으며, 충돌 해결이 구현될 필요가 없다는 장점이 있다. 또한 키가 데이터가 아니며 쿼리된 키가 유효할 것으로 알려진 경우 키를 룩업 테이블에 저장할 필요가 없으므로 공간이 절약된다.
완벽한 해시함수의 단점은 완벽한 해시함수의 구성을 위해 S를 알아야 한다는 것이다. S가 변경되면 비동적 완전 해시 함수를 재구성해야 한다. 자주 변경되는 S 동적인 완벽한 해시 함수는 추가 공간의 비용으로 사용될 수 있다. 완벽한 해시 함수를 저장하기 위한 공간 요구 사항은 O(n)에 있다.
완벽한 해시 함수를 위한 중요한 성능 매개 변수는 일정해야 하는 평가 시간, 구성 시간 및 표현 크기이다.
대부분의 일반적인 응용 프로그램에서 해시 함수와 테이블이 설계되고 사용되기 전까지는 어떤 키 값 집합이 해시되어야 하는지 정확히 알 수 없다.
그 시점에서 해시 함수를 변경하거나 테이블의 크기를 변경하는 것은 모든 키를 다시 해싱해야 하기 때문에 매우 비용이 많이 들 것이다.
완벽한 해시 함수 (Perfect Hash Function)는 충돌 없이 실제 키 값 집합을 테이블에 매핑하는 함수이다.
최소한의 완벽한 해시 함수는 해시할 키 값만큼의 슬롯만 있는 테이블을 사용한다.
키 집합을 미리 알면 완벽한, 어쩌면 최소한의 완벽한 특수 해시 함수를 구성할 수 있다.
완벽한 해시 함수를 구성하는 알고리즘은 복잡하지만, 많은 perfect hash function들이 알려져 있다.
#Cichelli’s Method
Cichelli’s Method는 주로 프로그래밍 언어를 위해 예약된 단어들의 집합과 같이 상대적으로 작은 키 집합을 가질 필요가 있을 때 사용된다.
기본 공식은 다음과 같다:
h(S) = S.length() + g(S[0]) + g(S[S.length()-1])여기서 g()는 h()가 집합의 각 단어에 대해 다른 해시 값을 반환하도록 Cichelli’s 알고리즘을 사용하여 구성된다
- 이 알고리즘은 3단계로 구성되어 있다
- 단어의 문자 빈도 계산
- 단어의 순서를 정하기
- 탐색
아래 목록의 단어를 해시해야 한다고 가정해보자

각 첫 글자와 마지막 글자가 발생하는 빈도를 계산해보자

처음과 마지막 글자의 빈도를 합산하여 단어의 점수를 매긴 순서로 정렬해보자
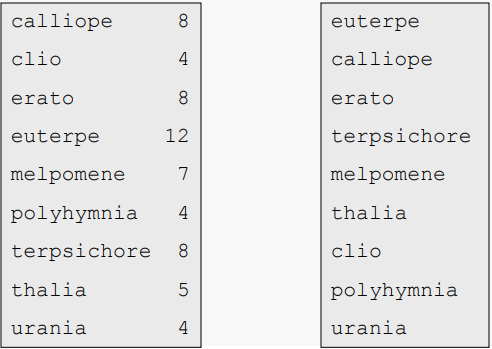
마지막으로, 단어들을 순서대로 고려하고, 각각의 단어들이 고유한 해시 값을 가질 수 있는 방법으로 각각의 가능한 첫 글자와 마지막 글자에 대해 g(x)를 정의하자
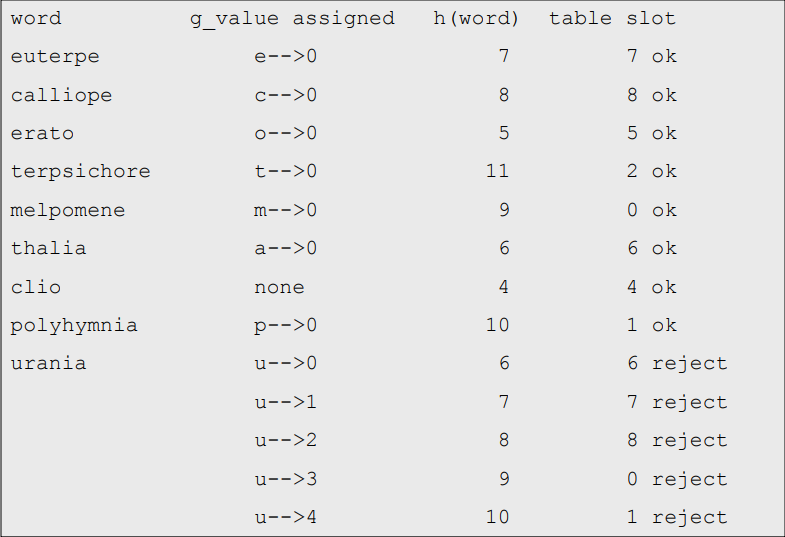
Cichelli의 방법은 이 시점에서 검색에 제한을 가하므로 이전 단어로 백업하고 매핑을 다시 정의한다.
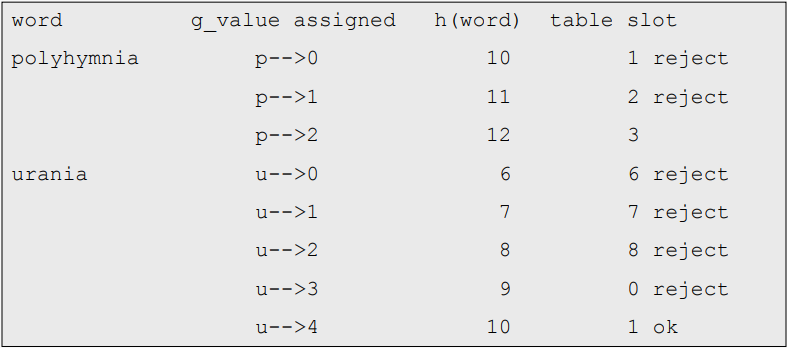
따라서, 위에서 결정한 대로 g()를 정의하면, h()는 주어진 단어 집합에 대한 최소한의 완벽한 해시 함수가 될 것이다. 검색 단계가 지수 성능으로 저하될 수 있으므로 작은 단어 집합에 대해서만 실용적이기 때문에 주된 단점은 비용이다.
#Table Size with Probing
프로브 전략을 사용하여 충돌을 해결하는 경우, 테이블 슬롯의 70% 이상이 채워지면 검색 성능이 크게 저하될 가능성이 있다고 알려져 있다. 특히 테이블에 N개의 슬롯이 있고 K개의 요소를 저장하는 경우 검색에서 수행되는 평균 비교 수는 다음과 같다
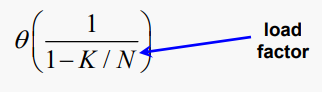
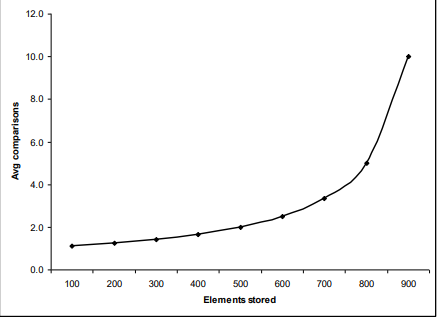
N = 1000을 취하고 이것을 그래프로 나타내면 다음과 같다
#Re-hashing
프로브 전략을 사용하여 충돌을 해결하는 경우 테이블의 부하 계수가 너무 커지면 테이블 자체의 크기를 조정하도록 선택할 수 있다. 그러나 이를 위해서는 이전 배열의 모든 데이터 요소를 새 배열로 복사해야 할 뿐만 아니라 모든 키 값을 다시 해싱해야 한다 (또는 최소한 나머지를 다시 계산해야 함). 그렇더라도 충돌에 대처하기 위해 탐색 전략을 채택하고 테이블 성능이 저하되면 대안이 거의 없다.
#Table Size with Chaining
체인을 사용하여 충돌을 해결하는 경우 테이블이 실제로 채워지지 않는다.
검색의 평균 비교 횟수는 다음과 같다:
Θ(1 + K / N)1000개의 슬롯으로 구성된 테이블을 사용하는 경우 이전 예제와 비교하면 어떨까? 이것은 공평한 비교일까?
#기타 고려 사항
우리가 충돌을 어떻게 다루든, 우리는 충돌의 수가 적길 원한다. 이것은 테이블 크기와 관련이 있다. 그렇다면 충돌은 언제 일어날까?
다음과 같은 두 가지 키 값이 있을 경우
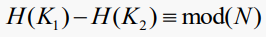
이제 그것은 다음과 같은 양의 정수 q가 존재하는 것과 같다
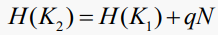
이것을 보는 또 다른 방법은 해시 함수가 congruents mod N인 값을 생성하고 가능한 congruents mod N의 수가 결정될 때 충돌이 발생한다는 것이다.
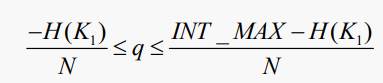
따라서, N이 클수록 가능한 합동(congruent)이 적다
#Prime(소수) 테이블 크기
테이블 크기는 소수여야 할까?
만약 체인이 사용된다면, 우리가 소수로 변조하는지 여부는 일치하는 슬롯 번호를 얻을 가능성에 영향을 미치지 않기 때문에, 문제가 되지 않는 것처럼 보인다. 그러나 프로브 전략을 사용할 경우 프라임 테이블 크기가 결과적으로 프로브 전략이 모든 테이블 슬롯을 증가시킬 수 있는 가능성을 개선할 수 있다(예: 2차 프로브 사용 시).
그러나 탐색을 통해 많은 테이블 슬롯을 검사해야 하는 경우, 애초에 해시 테이블을 사용하도록 동기를 부여했던 성능 비용이 이미 손실된 후이다. 그렇기에 소수 테이블 크기가 결과를 개선할 수 있는 몇 가지 해시 함수가 있다.
문자열을 취하고, 시프트 앤 애드(shift-and-add)방식을 적용하여 정수를 계산하는 문자열 해시 함수를 한번 보자.
r-비트 쉬프트를 사용하고 k바이트 문자열에 대해 다음과 같은 형식의 정수를 계산한다고 가정해 보자.
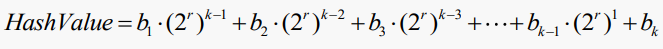
그러나 테이블 크기가 2의 거듭제곱(예: 2^r)이라면, 이에 따라 변조하면 낮은 바이트를 제외한 모든 부분의 기여를 무시할 수 있다. 그렇기에 테이블 전체에 키가 잘 분산되지 않을 것이다. 이러한 알고리즘에서 2의 거듭제곱으로 작업하는 것은 당연하므로 프라임 테이블 크기를 선택하면 이러한 효과가 없어진다.
'Computer Science > Data Structures & Algorithms' 카테고리의 다른 글
| [Lecture 7] 점근(asymptotic) 표기법/ Big-O 표기법 (1) | 2023.01.06 |
|---|---|
| [Lecture 6] Algorithm Analysis / 알고리즘 분석 (1) | 2023.01.05 |
| [Lecture 1] BST / Binary Search Tree / 이진탐색트리 (0) | 2023.01.01 |
| [Lecture 0 - II] Java Equals() & Generics (0) | 2023.01.01 |
| [Lecture 0 - I] Java File I/O (1) | 2023.01.01 |



